Overview
At the most basic level, DNSSEC provides the assurance for DNS servers and resolvers (a.k.a DNS clients) to trust DNS responses by using digital signatures for validation. Specifically, it provides origin authority, data integrity, and authenticated denial of existence of validated DNS responses.
When a DNS client issues a query for a name, the accompanying digital signature is returned in the response. Successful validation would show that the DNS response has not been modified or tampered with. Any subsequent modifications to the DNS zone (e.g. adding and deleting of records) would require the entire zone file to be re-signed.
Trust Anchor & PKI Concept
Before you can perform any digital signature validations, all involved parties must trust a common "authority" in higher level, in order to create a trust path beforehand. This "authority" is known as Trust Anchor, which is similar to the Certificate Authority (CA) in the PKI concept. Just like the PKI CA, it is also able to sign next-level child zones down under, such as child.abc.com if the trust anchor is on abc.com. Because everyone trust this common Anchor Point, the clients would also trust other "child zones" vouched by this "authority".
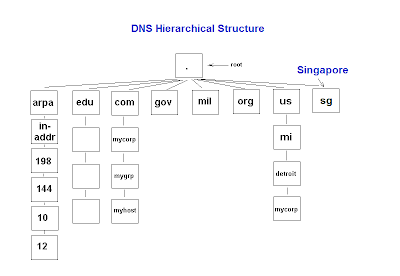
Do note that zone signing is only required for authoritative DNS servers. Remember that the DNS cache poisoning attacks are mostly targeted at the local DNS server caches of your ISPs. These recursive resolvers do not need to be signed by the root zone, as they are mostly non-authoritative (i.e. contain no zones on their owns) and simply perform recursive lookup on your behalf. The DNS resolvers belonging to the ISPs just need to be pre-configured to trust the public keys of the trust anchors - much like the Web browsers on your desktops that are pre-configured to trust the public certs of Verisign & Thawte.
New DNS Extension
To facilitate DNSSEC validations, four new resource records (DNSKEY, RRSIG, NSEC and DS) are introduced to existing DNS structure. DNSKEY (DNS public key) contains the zone public key. RRSIG (Resource Record Signature) contains the digital signature of the DNS response. NSEC (Next Secure) can inform about the denial-of-existence records. For example, if the zone only contains record A and D but you ask for B, it would return "A NSEC D" indicating the non-existence of records B and C. Lastly, DS (Delegation Signer) is used to validate between the parent and child zones, which are both DNSSec enabled.
IPSec
In most situations, the clients would simply ask the local DNS servers to perform DNSSec validation on their behalf. For maximum protection, you may also want to setup IPSec communications between the clients and the local servers. In corporate environments, these computers may use their domain certs for such domain IPSec setup. Note that IPSec is optional for DNSSec.
Name Resolution Policy Table (NRPT)
What if you wish to reject DNS response from non-DNSSec enabled DNS servers or making IPSec connection compulsory? You can influence such behaviours by the means of Name Resolution Policy Table (NRPT). Before issuing any queries, the DNS client will consult the NRPT to determine if any additional flags must be set in the query. Upon receiving the response, the client will again consult the NRPT to determine any special processing or policy requirements. In Windows Server 2008 R2 implementation, the following NRPT properties may be set using Group Policy:
1) Namespace: Used to indicate the namespace to which the policy applies. When a query is issued, the DNS client will compare the name in the query to all of the namespaces in this column to find a match.
2) DNSSEC: Used to indicate whether the DNS client should check for DNSSEC validation in the response. Selecting this option will not force the DNS server to perform DNSSEC validation. That validation is triggered by the presence of a trust anchor for the zone the DNS server is querying. Setting this value to true prompts the DNS client to check for the presence of the Authenticated Data bit in the response from the DNS server if the response has been validated, If not, the DNS client will ignore the response.
3) DNS Over IPsec: Used to indicate whether IPsec must be used to protect DNS traffic for queries belonging to the namespace. Setting this value to true will cause the DNS client to set up an IPsec connection to the DNS server before issuing the DNS query.
4) IPsec Encryption Level: Used to indicate whether DNS connections over IPsec will use encryption. If DNSOverIPsec is off, this value is ignored.
5) IPsec CA: Refers to the CA (or list of CAs) that issued the DNS server certificates for DNSSec over IPsec connections. The DNS client checks for the server authorization based on the server certificates issued by this CA. If left un-configured, all root CAs in the client computer’s stores are checked. If DNSOverIPsec is off, this value is ignored.